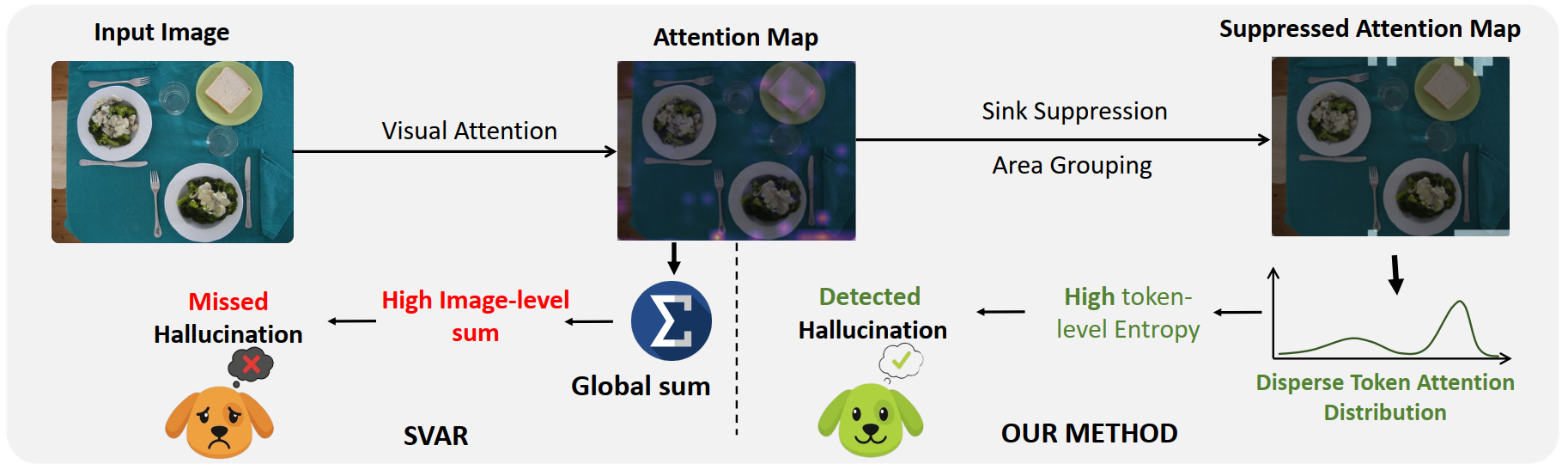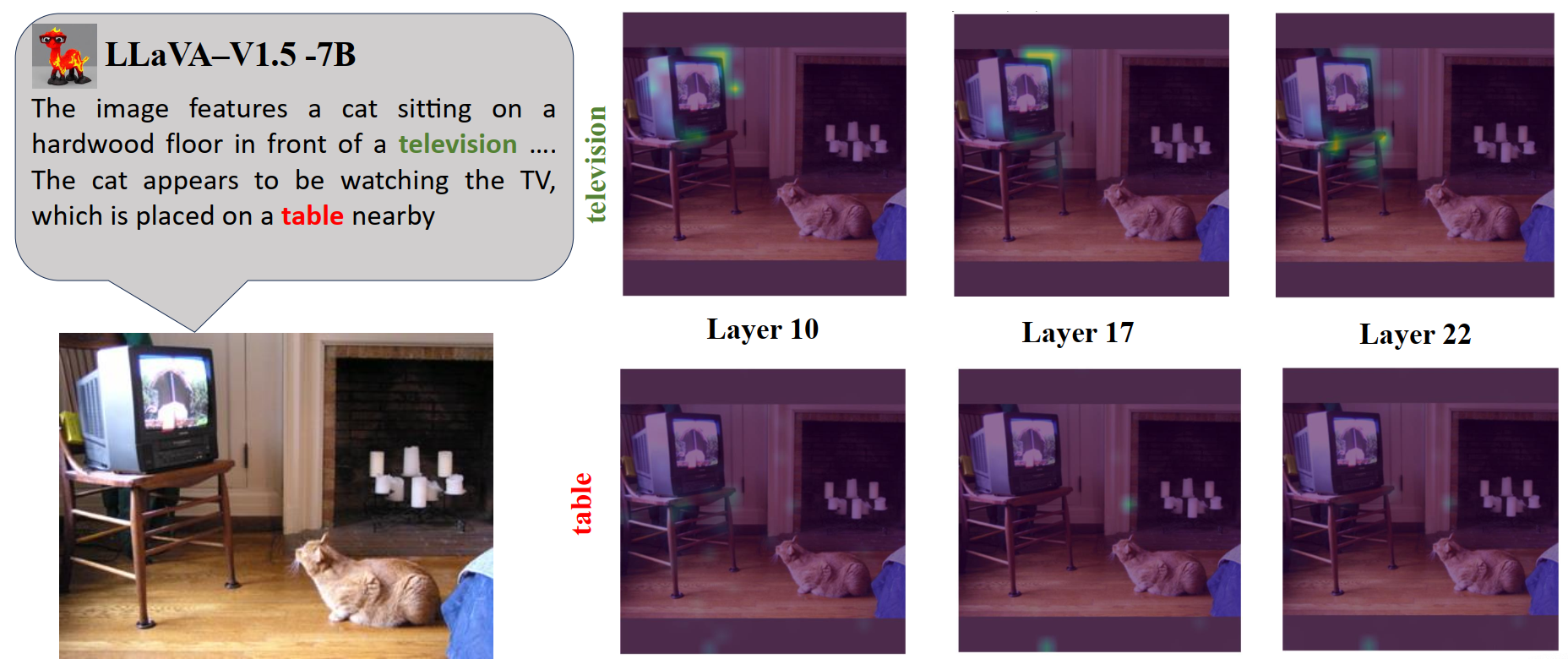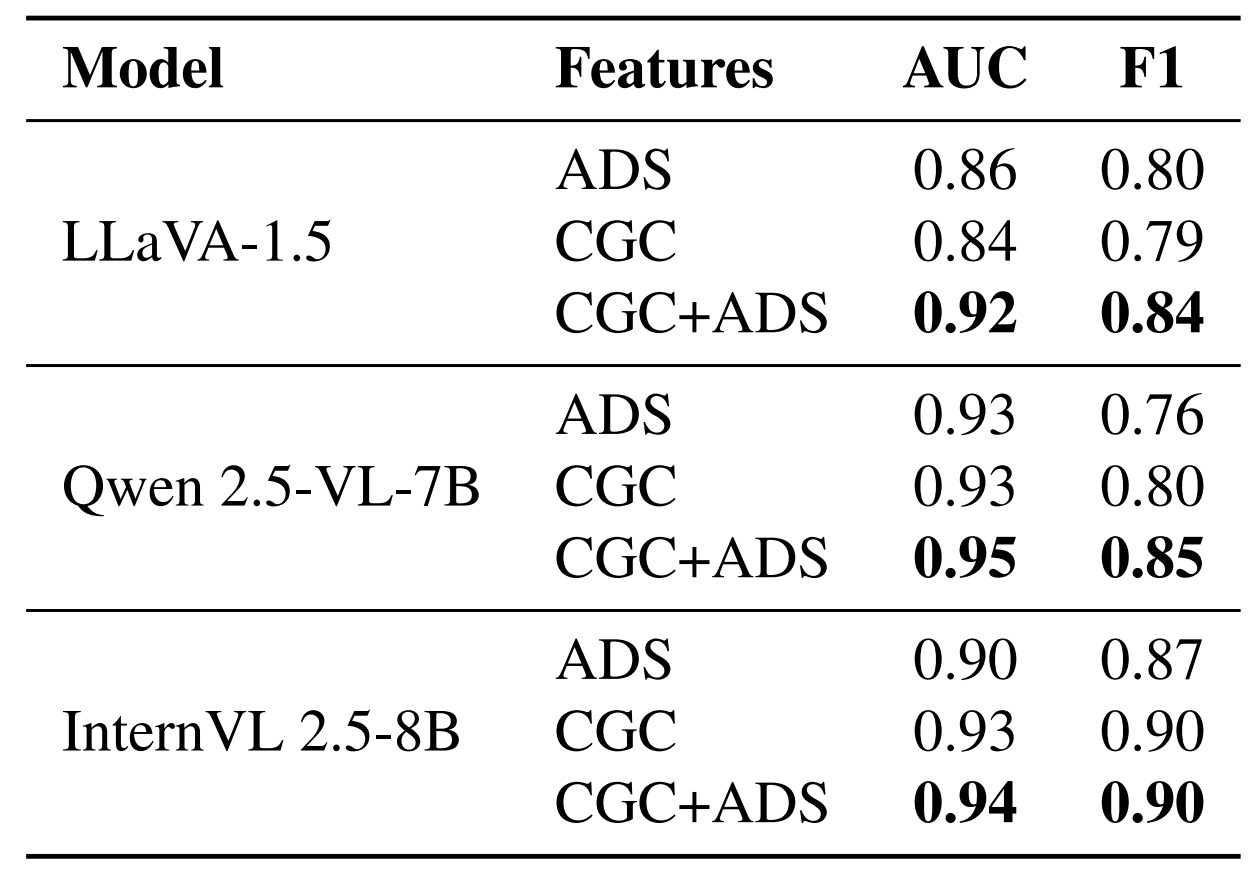
Figure 2. Overview of our token-level hallucination detection framework.
We propose two complementary metrics from LVLM internals — no external models, no LVLM retraining:
Attention Dispersion Score (ADS)
Measures the spatial compactness of cross-modal attention. We threshold the top-10% patches, group into connected components to suppress attention sinks, then combine foreground blob mass with background entropy.
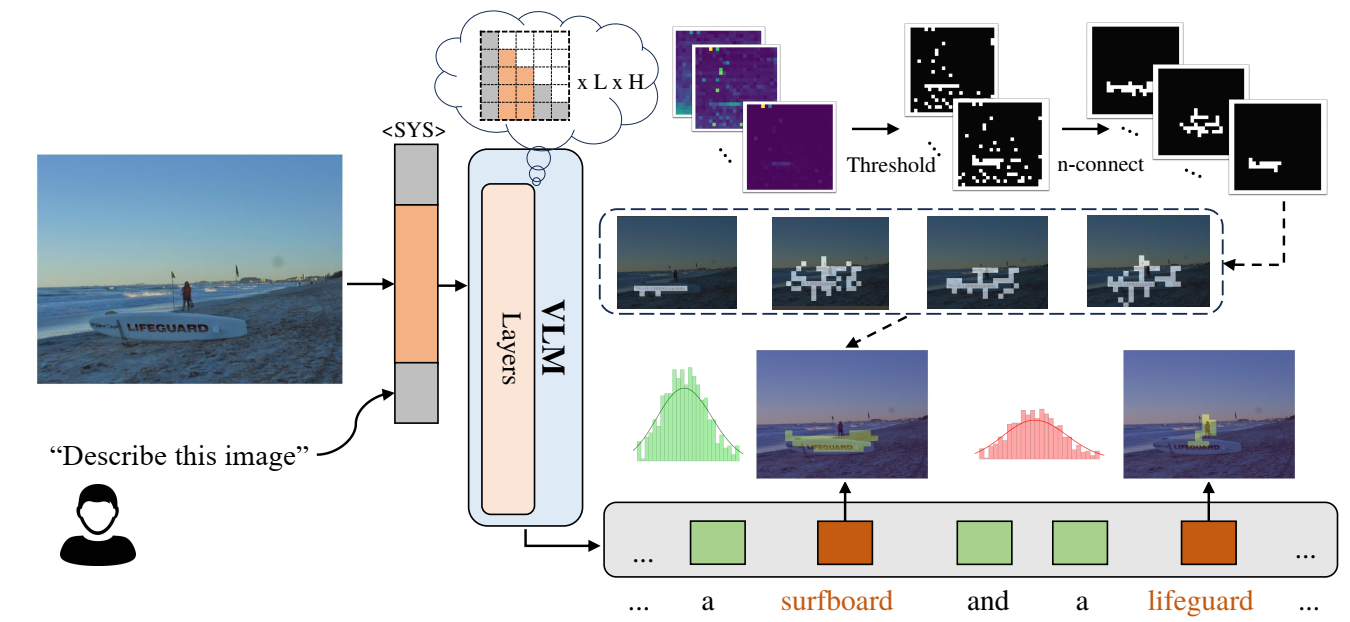
Figure 3. ADS pipeline: extract attention → threshold → connected components → entropy.
Low ADS → compact focus → grounded
High ADS → scattered attention → hallucinated
Cross-modal Grounding Consistency (CGC)
We evaluate the feature similarities between the generated token and image patches, and coin this metric as Cross-modal Grounding Consistency (CGC). At layer \(n\), let \(\mathbf{z}^{(n)}_t, \mathbf{v}^{(n)}_p \in \mathbb{R}^d\) be the token and patch embeddings, and define cosine similarity
\(S^{(n)}_{t,p} = \frac{\langle \mathbf{z}^{(n)}_t,\, \mathbf{v}^{(n)}_p \rangle}{\|\mathbf{z}^{(n)}_t\|_2 \;\|\mathbf{v}^{(n)}_p\|_2}\)
which reflects local structural alignment. The per-token map is \(\mathbf{S}^{(n)}_t = [S^{(n)}_{t,p}]_{p \in \mathcal{P}}\). To emphasize localized evidence, we obtain the token grounding score \(C^{(n)}_t\) by aggregating the top-\(k\) patches \(\mathcal{T}^{(n)}_t\):
\(C^{(n)}_t = \frac{1}{k} \sum_{p \in \mathcal{T}^{(n)}_t} S^{(n)}_{t,p}\)
High CGC → token aligns with specific visual content → grounded
Low CGC → no patch matches semantically → hallucinated
Per-layer scores are concatenated into a single feature vector for a lightweight classifier:
\(\mathbf{f}_t = [\,\text{ADS}_t^{(1)}, \ldots, \text{ADS}_t^{(L)} \;\|\; C_t^{(1)}, \ldots, C_t^{(L)}\,] \in \mathbb{R}^{2L}\)
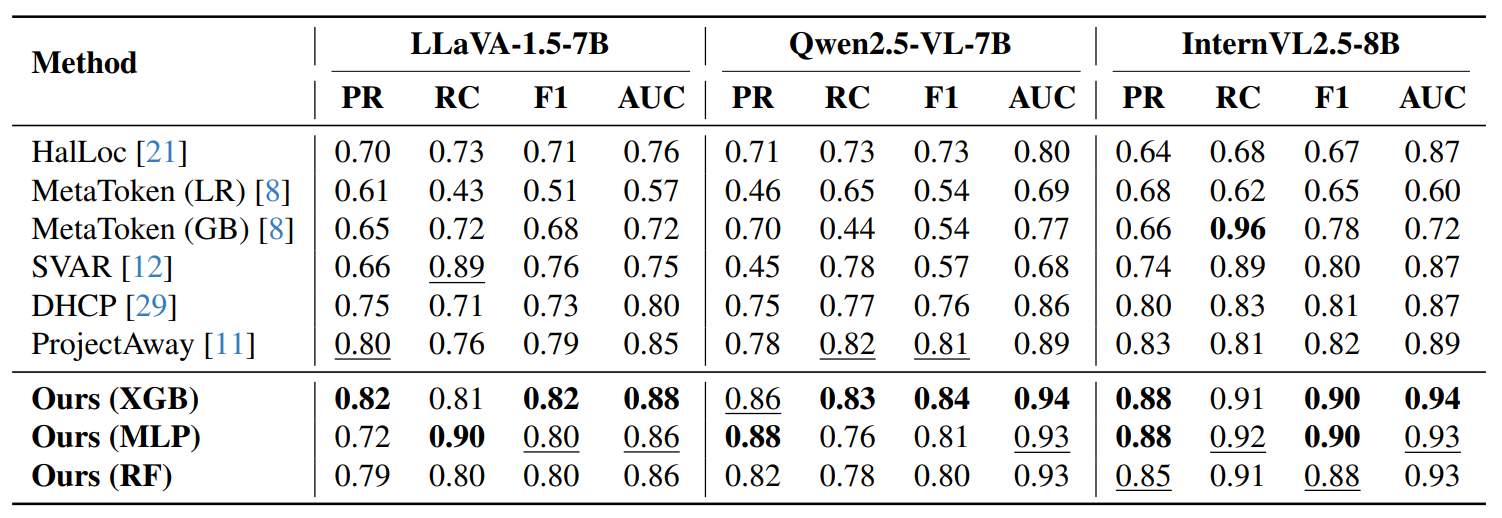
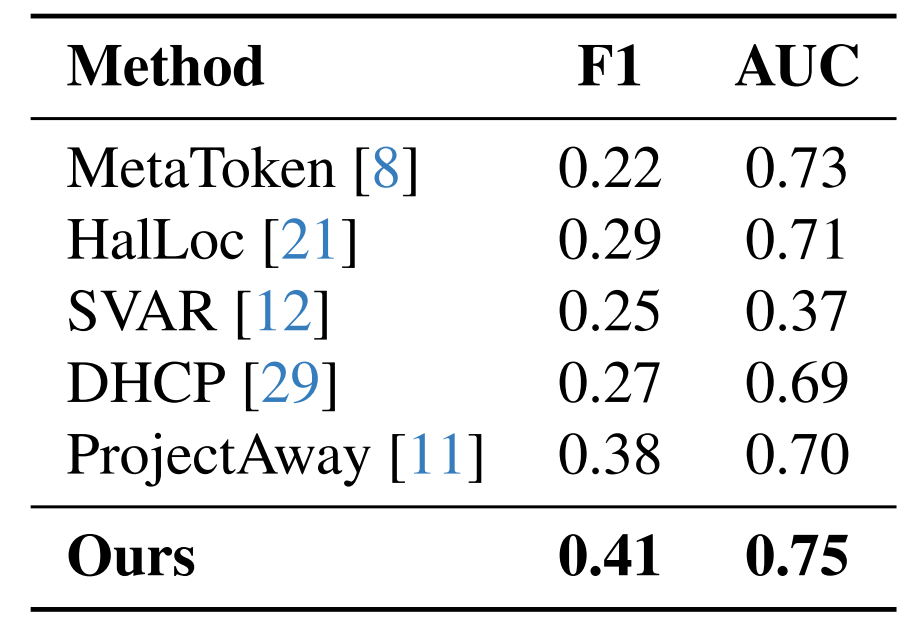
We train XGBoost, Random Forest, and MLP classifiers. Detection adds <1 second per token.